










Have you ever wondered how producers and DJs create those amazing remixes, where they isolate specific instruments from a song and turn them into a new track altogether? Well, one of the ways achieving this in this day and age of AI is by using Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs) in Python!
Music is a huge part of our lives and stereo music is a popular format we all love to listen to. But have you ever wanted to extract specific instruments from a track?
So, what are CNNs and RNNs? CNNs are a type of neural network used for image classification, but they can also be used for audio processing. RNNs are another type of neural network used for predicting sequences of data, like speech recognition. By combining these two types of neural networks, we can extract specific instruments from a stereo track using a technique called source separation.
To get started, you’ll need to install some libraries like Librosa, NumPy, TensorFlow or PyTorch, and Keras. These libraries allow you to load audio files, transform audio signals into spectrograms, build CNN and RNN models, and train them.
Once you’ve got your libraries set up, you can load a stereo audio file and its individual instrument tracks using Librosa. The next step is to convert the audio signal into a magnitude spectrogram, which is a 2D representation of the audio signal in the frequency domain. You can use Librosa’s “stft” function to do this.
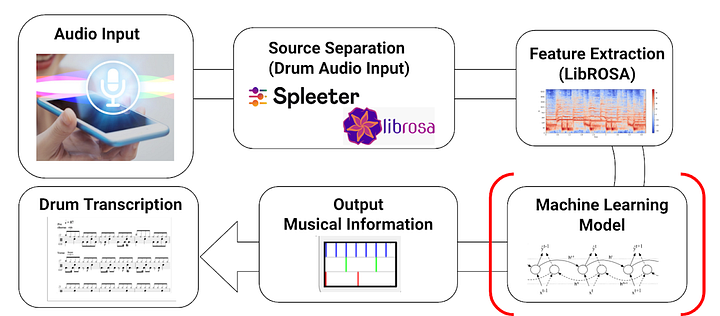
Python offers a wealth of libraries and resources to help you implement source separation using CNNs and RNNs to isolate instruments from stereo music.
1.To install the required libraries, you can use the pip package manager in Python. Here is an example command to install the necessary libraries
PYpip install librosa numpy tensorflow kera
2. Load the audio files:
You can use the librosa.load function to load the stereo audio file and its corresponding individual instrument tracks from the dataset. Here is an example code snippet:
import librosa
# load stereo audio file
mix, sr = librosa.load('path/to/stereo/file.wav', sr=None, mono=False)
# load individual instrument tracks
vocals, sr = librosa.load('path/to/vocals/file.wav', sr=None, mono=True)
drums, sr = librosa.load('path/to/drums/file.wav', sr=None, mono=True)
bass, sr = librosa.load('path/to/bass/file.wav', sr=None, mono=True)
other, sr = librosa.load('path/to/other/file.wav', sr=None, mono=True)
3. Preprocess the audio signal:
After creating a dataset of mixed audio and individual instrument tracks, which we will use to train our models. Then, we can use a CNN to extract features from the mixed audio signal and predict the magnitude spectrogram of each individual instrument track. The magnitude spectrogram is a way to represent the audio signal in the frequency domain. By predicting the magnitude spectrogram of each instrument track, we can separate them from the mixed audio signal.
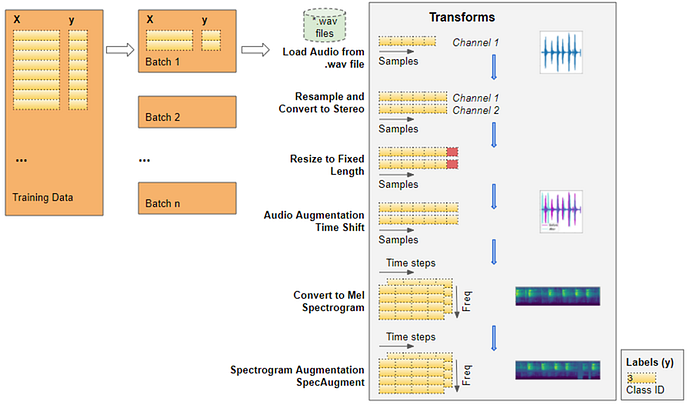
To convert the audio signal into a magnitude spectrogram, you can use the librosa.stft function. Here is an example code snippe
import numpy as np
import librosa
# convert audio signal to magnitude spectrogram
mix_spec = np.abs(librosa.stft(mix))# convert individual instrument tracks to magnitude spectrograms
vocals_spec = np.abs(librosa.stft(vocals))
drums_spec = np.abs(librosa.stft(drums))
bass_spec = np.abs(librosa.stft(bass))
other_spec = np.abs(librosa.stft(other))
4. Prepare the data:
To create the input and output data for the model, you can stack the magnitude spectrograms of the individual instrument tracks into a 3D tensor, and use the magnitude spectrogram of the mixed audio signal as the input. Here is an example code snippet:
# stack individual instrument tracks into a 3D tensor
y = np.stack([vocals_spec, drums_spec, bass_spec, other_spec], axis=-1)
# use magnitude spectrogram of mixed audio as input
X = mix_spec[..., np.newaxis]
5. Build the CNN and RNN models:
You can create the CNN and RNN models using the Keras API. Here is an example code snippet:
from keras.models import Model
from keras.layers import Input, Conv2D, MaxPooling2D, Flatten, Dense, LSTM, Bidirectional
# define input shape
input_shape = X.shape[1:]
# create CNN model
inputs = Input(shape=input_shape)
x = Conv2D(32, (3, 3), activation='relu', padding='same')(inputs)
x = MaxPooling2D((2, 2))(x)
x = Conv2D(64, (3, 3), activation='relu', padding='same')(x)
x = MaxPooling2D((2, 2))(x)
x = Conv2D(128, (3, 3), activation='relu', padding='same')(x)
x = MaxPooling2D((2, 2))(x)
x = Flatten()(x)
x = Dense(256, activation='relu')(x)
cnn_outputs = Dense(4, activation='linear')(x)
cnn_model = Model(inputs=inputs, outputs=cnn_outputs)
# create RNN model
inputs = Input(shape=(None, cnn_outputs.shape[1]))
x = Bidirectional(LSTM
(units=128, activation='relu', return_sequences=True))(inputs)
x = Bidirectional(LSTM(units=128, activation='relu', return_sequences=True))(x)
rnn_outputs = Dense(4, activation='linear')(x)
rnn_model = Model(inputs=inputs, outputs=rnn_outputs)
6. Train the models:
You can use the compile and fit methods of the Keras API to train the CNN and RNN models. Here is an example code snippet:
# compile CNN model
cnn_model.compile(optimizer='adam', loss='mean_squared_error')
# fit CNN model
cnn_model.fit(X, y, batch_size=32, epochs=50, validation_split=0.2)
# compile RNN model
rnn_model.compile(optimizer='adam', loss='categorical_crossentropy')
# fit RNN model
rnn_model.fit(rnn_inputs, rnn_outputs, batch_size=32, epochs=50, validation_split=0.2)
7. Evaluate the models:
You can use the evaluate method of the Keras API to evaluate the performance of the CNN and RNN models on a test set. Here is an example code snippet:
# evaluate CNN model
cnn_loss = cnn_model.evaluate(X_test, y_test)
# evaluate RNN model
rnn_loss = rnn_model.evaluate(rnn_inputs_test, rnn_outputs_test)
8. Apply the models:
To isolate instruments from new stereo music, you can load the stereo audio file, preprocess the audio signal into a magnitude spectrogram, and input it into the CNN and RNN models to obtain the predicted magnitude spectrograms of each individual instrument track. Finally, you can convert the magnitude spectrograms back into the time domain and save the individual instrument tracks as separate audio files. Here is an example code snippet:
# load stereo audio file
mix, sr = librosa.load('path/to/new/stereo/file.wav', sr=None, mono=False)
# convert audio signal to magnitude spectrogram
mix_spec = np.abs(librosa.stft(mix))
# use CNN model to predict magnitude spectrogram of individual instrument tracks
cnn_pred = cnn_model.predict(mix_spec[np.newaxis, ..., np.newaxis])[0]
# use RNN model to refine prediction of individual instrument tracks
rnn_pred = rnn_model.predict(cnn_pred[np.newaxis, ...])[0]
# convert magnitude spectrograms to time domain signals
vocals_pred = librosa.istft(vocals_pred * mix / mix_spec)
drums_pred = librosa.istft(drums_pred * mix / mix_spec)
bass_pred = librosa.istft(bass_pred * mix / mix_spec)
other_pred = librosa.istft(other_pred * mix / mix_spec)
# save individual instrument tracks as separate audio files
librosa.output.write_wav('path/to/new/vocals/file.wav', vocals_pred, sr)
librosa.output.write_wav('path/to/new/drums/file.wav', drums_pred, sr)
librosa.output.write_wav('path/to/new/bass/file.wav', bass_pred, sr)
librosa.output.write_wav('path/to/new/other/file.wav', other_pred, sr)
Now, it’s time to build your CNN and RNN models. The CNN model will take the magnitude spectrogram of the mixed audio signal as input and predict the magnitude spectrogram of each individual instrument track. The RNN model will refine these predictions by taking the magnitude spectrogram of the mixed audio signal and the predicted magnitude spectrogram of each instrument track as input and predicting the magnitude spectrogram of each individual instrument track.
Once you’ve built your models, it’s time to train them using your input and output data. You can use the Adam optimizer and mean squared error loss function for the CNN model, and the categorical cross-entropy loss function for the RNN model. After training your models, it’s time to evaluate their performance using metrics like mean squared error, signal-to-noise ratio, and source-to-distortion ratio. You can also visualize the predicted spectrograms to see how well the models are separating the individual instrument tracks.
So, isolating instruments from stereo music using CNNs and RNNs is a fun and challenging task that can lead to exciting results! Whether you’re a musician or just a music lover, this technique can help you extract specific instruments from your favorite tracks and create unique remixes. And with the continued advancement of neural network technology, who knows what kind of new music possibilities we’ll discover in the future!
















Add Comment